
"It is
impossible for ideas to compete in the marketplace if no forum for
their presentation is provided or available." � �Thomas Mann, 1896
Business
Continuity Management:
Justification, Implementation & Testing
by Paul H. Rosenthal - L. Jane
Park - Jan I. Weissman
Contributed by California State University, Los Angeles
Abstract
Information systems, both manual and automated, are essential to the survival of modern organizations, yet many firms do not have realistic, documented, and tested Business Continuity Management (BCM) Plans. �Prudent Person� officer responsibility therefore demands that all executives assure that their organization can survive a natural or man-made disaster that destroys or disables their manual or automated information systems. This paper presents and illustrates the justification approach needed to sell, and the methodologies used to document, implement, and test a BCM. It points out that the traditional probability based �Insurance� approach often leads to the incorrect result that the cost of a workable BCM exceeds the total costs incurred when a low probability disaster occurs.
Modern organizations have a large variety of operational and managerial functions whose continuous operations are critical to the organizations continuing viability. Business Continuity Management (BCM) involves arranging for emergency operations of these critical business functions and for resource recovery planning of these functions following a natural or man-made disaster. Business Continuity Management Plans are needed for all such organizational units, including data centers, information systems (IS) supported functions, and those organizational functions which are performed manually.
The widespread lack of a BCM Plan for many office buildings, data centers, and for most non-IS related operational and managerial functions is based on two mistaken beliefs:
-
That the chance that a disaster will occur is so remote that the responsible managers and
executives need not consider BCM as an essential part of their jobs, and
-
That, over the long term, the cost of a workable BCM exceeds the total costs incurred when a low
probability disaster occurs.
These beliefs are based on the incorrect use of insurance based �probability concepts� for risk assessment, instead of on �prudent person� risk assessment approaches. This paper will, therefore, present both the scope and procedures for developing and testing a BCM as well as a detailed discussion of justifying a BCM based on the �prudent person� approach. It is organized into the following sections:
-
Overview of Business Continuity Management
-
Development of the BCM field
-
Contents of a typical BCM Plan
-
Justifying and Developing a Business Continuity Management Plan
-
Phases in developing a typical BCM Plan
-
Prudent Person justification methodology and case study
-
Contents of a usable Business Continuity Management Plan
-
Functions of BCM Teams
-
Data Center Backup Architectures
-
Manual Systems Backup Approaches
-
Conclusion
OVERVIEW OF BUSINESS CONTINUITY MANAGEMENT
Experience in the information systems continuity planning area has demonstrated that disasters to quality business offices/facilities/data centers occur approximately once every hundred years. A disaster probability of 1% per year appears to be the proper basis of individual facility based Business Continuity Risk Assessment. This is actually a very high probability when the prudent business person realizes that the loss of a business facility containing critical functions can destroy the company. The advent of critical information systems applications, as discussed in Andrews [1], first brought this exposure to the attention of most executives.
DEVELOPMENT OF THE BCM FIELD
Prior to the development of computer based information systems that were critical to an organizations day-to-day operations, Business Continuity Management consisted primarily of insurance programs, life-safety oriented building evacuation plans, and mutual aid agreements for batch processing resources between data centers. By the late 1970s, computer based systems had evolved from batch back office and 2 accounting functions to online systems supporting critical business functions such as airline reservations systems and bank teller support applications.
To meet this new critical dependence on information systems, the Comptroller of the Currency issued a banking circular entitled "Contingency Planning for EDP Support" on May 26, 1983 to the national banks that it audited. The circular required that the banks prepare Contingency Plans for recovering their critical IS functions. This circular started the modern IS contingency planning support industry. The IS contingency planning support industry consists of two areas: consultants and packaged plans to assist an organization in developing their BCM, and shared commercial backup data centers for use following a disaster.
Support for developing a contingency plan
Several organizations sell an IS contingency plan development methodology including planning procedures and a sample plan available on a diskette. The sample plan is tailored, often with consulting help from the vendor, to the organizations individual requirements. The sample plans are often of great value to organizations that have not had prior experience. However, their use often leads to long wordy plans that are not read by potential emergency operations and recovery participants.
Shared backup data centers
Two large and numerous smaller organizations offer data center operations facilities containing operating computers (a hot site), fully equipped space for installing several additional computers (a cold site), and space for clerical and support personnel. Scheduled use of the hot site computer(s) is only for testing by the eighty to a hundred clients of the hot/cold site facility. These commercial backup sites are extremely valuable after a localized disaster that makes a data center unavailable, but are subject to prior or multiple occupancy following a wide spread disaster affecting many facilities.
The availability of these support services and facilities has made data center disaster planning easily affordable for all but the largest companies.
By the late 1980s, external auditors were demanding that all organizations with critical IS applications have contingency plans that included not just their data center but its users as well. The term Business Continuity Management started to be used as IS contingency planning methodologies was expanded to cover all critical functions (automated as well as manual) of an organization. However, the availability of commercial data center backup facilities makes Business Continuity Management easier for automated functions than for manual functions. In fact, some business functions based on manual processing can develop economically justifiable backup procedures only by automating their critical functions.
CONTENTS OF A TYPICAL BCM
The typical Business Continuity Management contains three types of information: backup resource arrangements; BCM procedures for notification, activation, mobilization, and emergency operations; and listings of equipment and other resources at all facilities. It requires two very different formats, which is the information needed before and after a disaster.
BCM information needed before a disaster
A formal BCM plan is needed for orientation of employees that will be involved in activating the plan and performing emergency operations. Orientation material is also needed for all employees in both the life-safety and BCM areas. Detailed emergency operations plans are also needed both before a disaster for use during testing, and after a disaster for use during emergency operations. The type of information needed includes: Backup resource arrangements - The initial and most critical activity in creating a realistic BCM, is arranging for backup resources and data for use after a disaster.
Data centers with critical online applications either use commercial backup centers or utilize dual data center architectures. IS users and manual processing organizations also need to have backup space and resources available. Most organizations have space and equipment occupied by non-critical processing activities (such as development organizations, conference rooms, exhibit space, executive offices, etc.) that can be utilized in an emergency, given sufficient planning.
The lack of copies of paper based data, forms, and procedures is the most common weakness in BCM arrangements. Data centers routinely send copies of all data files to off-site storage daily.
Manual processing organizations must also store copies of all critical data off-site, frequently as microfilm. The loss of desk-top papers, diskettes, and Rolodexes can cripple organizations.
BCM procedures- BCM procedures documentation for use before a disaster are for employee orientation, BCM participant training, operational and simulation testing, and auditing activities.
The typical contents of a BCM are as follows.
-
Applicability
-
Distribution list (Controlled)
-
Organization structure (Team definitions)
-
Notification trees (Business and home numbers)
-
Activation and mobilization procedures
-
Backup resources (Locations and functions)
-
Emergency operations policies (For each business functions teams)
-
Resource recovery policies
-
Testing and training policies
-
Appendixes (copies of material for use following a disaster)
-
BCM information needed after a disaster
BCM activities- BCM activities documentation for use following a disaster should be concise and consist primarily of tables and charts. Lengthy statements of policy and detailed procedures are not read and typically ignored during an emergency. Effective BCM documentation for use following a disaster must contain:
-
Employee emergency reference cards
These site specific wallet size cards are distributed to all employees. They should contain both life-safety and BCM information such as assembly locations, emergency operations policy, and numbers to call for information.
-
Notification/Activation reference cards
These fold over pocket size cards contain a management call-tree, key assembly and backup resource addresses and telephone numbers, and emergency team contact information.
-
Team emergency operations procedures
Detailed team operations procedures are normally needed only when multiple locations performing the same business function exist. Such locations require detailed procedures since they are normally not staffed with the senior personnel needed to adapt policy level directives to the specifics of a particular emergency. This type of procedure is lengthy and difficult to prepare since it must anticipate various types and levels of disasters.
-
BCM reference information
Reference information is often included in the appendix of the BCM as well as being bound separately for ease of use following a disaster.
-
Emergency Team reference cards
These fold over pocket size cards contain the team member call-tree, an activity checklist, and backup resource information. Typical teams include: policy, emergency operations center, facility management, site recovery, backup data center operations, logistics, off-site storage coordination, floor wardens, assembly site coordinators, public/employee communications, telecommunications, etc.
-
Resource Tabulations
These tabulations contain such information as: lists of all resources by location including replacement information and backup resource locations; where all personnel are to report during emergency operations; and where to forward data and materials from off-site storage.
The best BCM documentation for use following a disaster that the author has observed consisted of approximately a dozen reference cards, several books of resource tabulations, and two well equipped EOCs.
JUSTIFYING AND DEVELOPING A BUSINESS CONTINUITY MANAGEMENT PLAN
The funding, security, planning, and testing phases of developing a BCM Plan are presented in this section, followed by a simulated conversation presenting a detailed analysis of the prudent person justification methodology as applied to the funding phase. A more detailed discussion of the justification approach can be found in Waldman [10].
PHASES IN DEVELOPING A TYPICAL BCM PLAN
Building a quality Business Continuity Management Plan is a lengthy process involving many persons and disciplines. Most organizations first build an IS data center plan, then a BCM for each critical data center user, and finally attempt a BCM for their critical manual processes. The following four phases apply to each of these functional areas.
-
Phase I - Funding
The initial step in any BCM program is that of obtaining the substantial funding normally required. This requires convincing the Board of Directors on the reality of a possible disaster and its probable impact on the ability of the organization to survive.
A detailed quantitative approach to a risk analysis is used widely. The approach is popular with government and large decentralized industrial firms with major consulting budgets see Wong [11]. It determines the probability of various man-made and natural disasters occurring and their impact on key business functions. The results present probability estimates that are difficult to translate into risk-cost protection decisions. Additionally they are actuarial based and do not apply to business decisions involving a single site or resource.
The board of directors of most firms responds far better to a fiduciary responsibility based risk analysis. A list of risks to which the firm's facilities and personnel is exposed is presented and a case study approach is used to demonstrate realistic risk exposure as in Waldman [10]. Estimates are made of the financial impact on various business functions, computer related and non-computer related, of a loss in resource capability. When the impacts include financial or service level losses that can effect the firm�s survival, then the board members fiduciary responsibility requires a prudent level of protection and recovery capability. Funding for an adequate BCM is then made available, often as a priority project.
-
Phase II - Disaster Prevention
Following initial funding, the next step in the BCM program, is to determine the possible extent of exposure to natural and man-made disasters of critical resources; including facilities, data, and personnel. Procedures must then be implemented to minimize the probability of such disasters occurring. Physical security planning primarily involves access controls, fire and water protection, earthquake and storm hardening, and critical records security. Most firms have a physical security program in place covering these areas prior to the implementation of a BCM program. The next step in the BCM is, therefore, simply an assessment of the program, and improvement if necessary. The author's experience indicates that the critical records area, particularly for non-computerized files, frequently is a major weak point.
Data security and protection programs are not as wide spread as physical security programs. Few firms have high quality data oriented security programs involving off-site backup storage of critical paper based financial & personnel records. Protection in this area frequently requires a major effort.
-
Phase III - BCM Planning
Disaster planning, as illustrated in Rohde and Haskett [6], is often initiated by the organization's data center, as it first implements applications critical to the day-to-day operations of the organization. The selling of data processing oriented disaster planning to the Board of Directors often alerts them to the risk presented by the non-computerized portions of the firms operations, and a total disaster recovery planning effort is initiated.
A team effort is the best approach to creating an organization's initial BCM. The team should include at least a person experienced in BCM architectures and plan development; a person with long term responsibility for developing and maintaining the plan; and an influential manager with in-depth knowledge of the organization, its operations, and its people. The team should move through the development cycle backwards and then forward.
-
Step 1 - for the various major resources of each business unit; determine the potential recovery architectures available, their costs, and the recovery periods they offer.
-
Step 2 - perform a risk analysis determining which resources are truly critical to the organizations survival. For those resources, determine their desired recovery periods and the most practical recovery architecture approach for each.
-
Step 3 - present a business resumption policy to the Board of Directors balancing risk, costs, and service levels.
-
Step 4 - create a detailed design of the authorized recovery architectures and assist each business unit in creating a business resumption policy and architecture.
-
Step 5 - assist each business unit in designating a BCM coordinator, assigning a planning team, and assisting them in developing and testing their plan.
-
Phase III - BCM Testing
Desk-top walk through - Before any detailed testing, key stakeholders in each business function's BCM are convened in a conference room, and a detailed review is performed of the plan. Many small events are described and the participants are asked to state how the plan would guide their reactions. The events should require utilization of: major backup resources, emergency operations approaches, and all emergency response teams. Following this step, operations and simulation tests are scheduled.
Operational testing - Few organizations operationally test the complete disaster reaction cycle of: activation, life-safety, damage assessment, mobilization, emergency operations using off-site files and backup resources, and recovery planning. Only the data processing emergency operations area can normally be tested without involving a substantial number of persons during business hours. The scope of most operational tests therefore, includes: a semi-annual off-hour call to the manager of data center operations, assembly of the backup site operations team, acquisition of backup materials from an off-site location, travel to a backup hot/cold site, installation of systems and applications software, loading production data, and systems test of several critical applications.
Simulation testing - Simulation is the most feasible approach for testing the decision making aspects of disaster reaction activities; see Rosenthal [8 & 9]. The use of simulation exercises for testing a BCM has been spreading slowly over the last decade. Unlike their military counterpart, war games that use computer driven scenarios to perform very realistic exercises, BCM exercises are paper and pencil simulations. Teams are placed at tables representing their backup locations, and the description of an evolving disaster is presented. The teams communicate using backup communication resources or forms, make decisions, and everyone pretends that what is ordered actually happens. Debriefings and evaluation studies follow to correct any flaws in the BCM.
-
A scenario for use in simulation testing of a BCM must fulfill several objectives.
Objective I - Be solvable for a majority of the business functions participating, using existing plans and backup resources. Except under very unusual political conditions, a major failure during a simulation test is not a suitable motivator for improvement in disaster planning, or for acquiring additional funding for backup resources. A primarily positive experience however, appears to be a powerful motivator to obtain additional funding to complete planning and backup resource acquisition. In fact, the scheduling of a simulation is often the easiest way to motivate organizations to update their staffing and contact lists. Proper planning of a scenario includes the review of each participating organization's BCM to determine if they can perform emergency operations at an acceptable level. If they cannot, a discussion with top management is appropriate, and warnings to the deficient organization's management is always proper (e.g., there should be no major surprises or disappointments)
.
Objective II - Represent a realistic risk - A fire, flood, earthquake (in California), or bomb is normally the basis for a scenario. A detailed knowledge of the buildings, area, and emergency services involved is always necessary. The disaster and its effects over several days or weeks has to be described, so that the participation of facility and security personnel is required.
Objective III - Capable of being partitioned into practical time steps Simulation exercises with four to six time steps are the most practical. Each time step must meet the following criteria:
a) The external and internal environment should change in terms of both the evolution of the events causing the disaster, and in terms of emergency and recovery efforts (e.g., new information given to participants and new actions required).
b) Each team should have some significant action they must accomplish (e.g., a decision, announcement, a report to management).
c) Time allowed for the time step should be sufficient but not generous (normally 30-60 minutes). The period simulated becomes longer with each time step in the simulation. The simulations performed to date indicate that the initial period simulated is often one to four hours, while the final period simulated is often several days to a week.
.
Objective IV - Be self documenting - Messages and plans produced during the simulation exercise should be rigidly formatted and documented, so that there is a detailed record of all events and actions. This documentation, together with the umpires and evaluators check lists, is necessary for later analysis. Most simulation exercises are very successful in that they force personnel to learn the BCM while working together, and find flaws and inconsistencies in emergency operations and recovery policies and plans.
PRUDENT
PERSON JUSTIFICATION METHODOLOGY
There is a substantial methodological and financial difference between data
center and manual business functions risk management decisions using
'prudent business' and traditional 'probability' based methodologies. There
is also a vast difference between risk management of a data center's
processing of the record keeping applications of the 1960's through the
early 1980's, and the risk management of the critical on-line operational
applications of the late 1980's through the 2000's. The hypothesis of
Waldman�s thesis [10] is that the probability based approach, created for
the record keeping applications of the early years of Information Systems
(IS), is no longer appropriate for the mission critical applications of the
1990's, and has never been appropriate for critical manual systems.
-
The prudent person methodology is based on executives eliminating those alternatives that risk the short and long term viability of the firm, and analysts then selecting the lowest cost alternative that provides acceptable recovery times. The prudent person duty of care test requires that an officer make a �reasonable investigation and honestly believe that their decision is in the best interest of the corporation�, see Metzger et al. [4].
-
The probability based approach is based on analysts multiplying the potential loss experienced following a disaster by the probability of it occurring, and comparing that to the cost of backup alternatives. As an example, the IBM approach as defined in Wong [11], states that �For each system: 1) the expected frequency of occurrence per annum, P, as well as the loss incurred, V, are calculated, and 2) the exposure, E, per annum is then evaluated from the values of P and C�. This approach often exposes the organization to unacceptable losses when a very low probability disaster actually occurs.
BCM Justification Example
A comparison of these approaches is illustrated in the simulated conversation that follows. It is extracted from a speech by the authors to the San Fernando Valley Association of Contingency Planners. The illustration involves a simulated discussion between an executive, an insurance oriented financial analyst (Mr. Probability) and a management systems oriented MIS planner (Mr. Application). The discussion is as follows.
Mr. Executive Speaks
"Mr. Probability, I understand you do not agree with Mr. Application�s request for a budget increase of $500,000 per year to implement a contingency planning program for our computer and data communication systems, as well as for semi-annual testing using a commercially available data center back-up site. Why do you feel the expenditures are financially unjustified?"Mr. Probability Speaks
"Mr. Executive, I have contacted the proposed data center backup site vendor and requested his experience over the last decade concerning how often a data center suffers a disaster. They have found that each of their backup centers with subscription levels of approximately 100, are used approximately once a year for other than reactive testing or planned conversions. I am therefore stating that a data center disaster is a once in a hundred year occurrence."
"Secondly, Mr. Applications request indicates that the old data center, that was replaced ten years ago because of security and size consideration, is still functional as a backup site capable of processing our production operations within a week following emergency ordering of equipment. As he states, it can be populated with computers etc. within a week and the CIS department could have our production systems current in two weeks. The backup data center he wishes to subscribe too, plus our testing expenses, will cost $50,000 per month and would permit him to have our productions systems current in two days. We are therefore computing that $500,000 per year is worth 10 days of operational losses.
"Thirdly, Mr. Applications indicates that direct losses due to non-current production systems are $3,000,000 per day. This figure was arrived at by accounting based on lost contributions to overhead and profit of three days sales.
"Lastly, if we multiply the $3,000,000 by 10 days we get $30,000,000 additional potential loss in a disaster if we do not subscribe for the commercial backup center. However when we divide this figure by 100, the probability of loss per year, we get a value of the commercial backup center of $300,000 per year. This net loss of $200,000 per year is obviously a bad investment of capital."
Mr. Executive Speaks
"Mr. Application, if your figures show such a bad investment, why have you proposed the contract?"
Mr. Application Speaks
"Mr. Probability does not understand the implications of ten days down time, now that our production applications are online. It is no longer a question of lost sales but of retaining customers� business after the ten day outage. I have had extensive conversations with marketing and customer service management. They feel that half our customers can tolerate a 10 day wait and will continue to buy from us. However marketing believes it will take several years to win back the other half of our current customers. Their optimistic figure of an average of a year to resell a customer will give us an additional loss of $18,000,000 ($3,000,000 times one-half times 240 days). This will give us a total loss of $48,000,000. If we then divide by 100 we get a return of $480,000 per year on an investment of $500,000. E.g. a break-even situation. �However, this type argument, including the division by 100, is irrelevant. The problem is that the data center could be destroyed tomorrow, or next year or not for 200 years. If it is destroyed and we did not take prudent steps to safeguard this critical business resource, we will all lose our jobs and be subject to stockholder suites. �The loss of approximately $48,000,000 is almost half of our annual profits. Additionally the loss of half our customers and the reduced service level for the remainder will ruin our reputation for service that is our future. We may never recover, let alone gain back the business we lost in a year on average. "I therefore recommend that, as a prudent business executive, you must protect such a critical resource as our data center and give us the $500,000 per year additional budget which is an addition of 2% to our total budget.�
This simulated discussion illustrates how subtle aspects in the presentation of information can significantly impact decision making-particularly when uncertainty is involved. Throughout the literature on decision making, there is substantial evidence to suggest that intuitions about risk routinely deviate from rationality, because executives do not typically appreciate the nature of uncertainty. This simulated discussion illustrates that the decision on how much safety is worth, is very difficult.
A BCM Justification Case Study
This BCM justification case study that follows presents both the probability based method and the recommended methodology based on �prudent business person� concepts. The recommended approach justifies the cost of data center contingency planning based on the total cost and impact to the organization when their information technology resources are unavailable. More details on this case study are available in Waldman [10].
Risk Analysis
This example is based on a consulting study, performed during in the late 1990's, of a wholesale distributor�s data center contingency planning project. The planning project determined that the proposed security and data protection plan would leave their data center vulnerable to natural and man made disasters, such as: fire, earthquake, utility interruption, and strikes. The objective of the planning study was to recommend an architecture that provided for continued processing of their critical applications. These included order processing, inventory management, accounts receivable, and payroll.
Alternative Scenarios
Four alternative BCM architecture scenarios were available. These were: a dual center approach, use of a vendor hot/cold site, use of a current company facility as a cold site, and continuation of their current approach with no backup resources.
-
The dual center approach involves the construction of a new secure data center facility, as well as the splitting of processing between the current and the new center. The typical 9 approach for this type of architecture is discussed in detail in the article by Rosenthal [7], entitled �The Emerging Enterprise System Architecture�. The expected maximum down time after a disaster using this approach is several hours.
-
The vendor hot/cold site approach involves subscribing to a commercial recovery center with compatible mainframe systems. The expected maximum down time after a disaster is several days.
-
The cold site approach involves the equipping of a current warehouse facility with all environmental and communication facilities required to quickly install a duplicate of their current data center. The expected maximum down time after a disaster is several weeks.
-
A continuation of their current no backup resource approach will lead to a expected maximum down time, after a disaster, of several months.
Forecasted Annual Expenses
Table 1: Annual Scenario Expenses, presents the then estimated annual expenses of each scenario. The total annual information technology budget for the organization approximates $12,000,000. The dual data alternative with down-time of several hours represents approximately 6%, and the vendor hot/cold site alternative with down-time of several days represents approximately 2%of the annual IT budget.
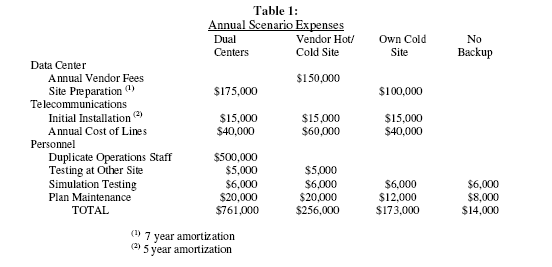
Step 1: Forecasted Annual Losses
The following analysis presents both the losses incurred by the organization during recovery of normal information technology processing, the losses incurred in winning back any lost customers, and reestablishing their service level reputation.
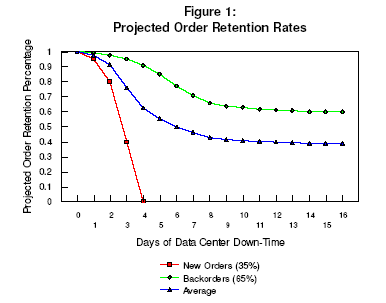
Step 2: Estimated Order Retention Rates
Figure 1: Projected Order Retention Rates were derived from interviews with key marketing and management personnel. As a wholesaler, the organization believes their customers would switch to alternative suppliers for new orders within four days. This would be caused by the lack of inventory information and the delays in picking and shipping cause by reversion to a slow manual operation and a shortage of trained personnel. They also estimate that reorders of proprietary items, representing 65% of reorders, would continue, but reorders of generally available items would stop over a 10 three week period. Figure 1, is derived in the spreadsheet included in Appendix A of Waldman [10].
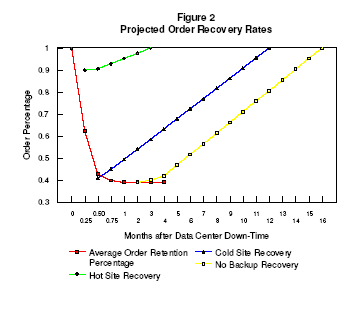
Step 3:
Estimated Order Rates
Figure 2: Projected Order Recovery Rate after a Disaster, presents the
estimated rates of recovery of orders following an interruption due to lack
of IT capability after a disaster. The key marketing and management
personnel believe the firm could recover approximately 5% of their former
order rate per month after return of full IT capability. However, recovery
from the vendor hot/cold scenario is slower, since all lost orders were new
orders. Figure 2, is also derived in the spreadsheet included in Appendix A
of Waldman [10].
Step 4: Forecast Economic Impacts
Table 2: Economic Analysis of Scenarios computes the impact of the scenarios from both the Probability and the Fiduciary Responsibility approach. The result of the analysis shown in Figure 2, is the estimated weeks of lost sales shown as the first data line in Table 2
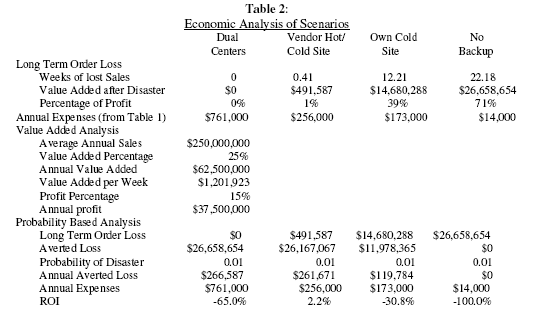
From a fiduciary responsibility view, the scenarios have the following impact.
Fiduciary Responsibility Analysis Approach
The use of the following recommended fiduciary responsibility approach is illustrated for each of the defined scenarios.
-
Dual Center Alternative
There are no losses associated with the dual center approach, since the impact of a disaster is not different from a routine interruption due to hardware, software, telecommunication, or utility failures. The costs of this alternative approximates 6% of the total IS budget, and 1.2% of the firm�s operating expenses. The firm, as typical of most distributors, did not believe the cost of dual data centers was worth saving a day�s down-time.
-
Vendor Hot/Cold Site Alternative
Losses from a disaster using this alternative will be approximately $500,000. This represents, as shown on the third data line of Table 2, about 1% of annual profits. This level of loss is acceptable, given the minimal probability of a disaster to the data center. The cost of approximately $250,000 for this alternative is 2% of data center costs. This is the alternative selected by the firm, an action typical of most business organizations.
-
Own Cold Site Alternative
This approach would lead to an estimated loss of approximately $15,000,000 which represents 40% of annual profits. This has a major impact on the company. The management thought this type of loss would cause the board to totally replace management of the firm, and might result in selling it to a competitor. This level of loss was simply not acceptable.
No Backup Alternative
This approach would lead to an approximated loss of $30,000,000. This represents a loss of 70% of annual profits, which would be a disastrous impact on the company. The board would immediately have to sell the firm, or cease operations. This level of loss was totally unacceptable.
Probability Analysis Approach
The data for a probability analysis of the distributor�s data center contingency planning is also included in Table 2. The result of a typical analysis of the data follows.
-
Dual Data Center Alternative
This alternative averts all loses, since recovery takes only a matter of hours or shifts. Using the typical one percent probability, the averted annual cost is approximately $270,000. This potential gain is balanced against the annual additional expenses of approximately $760,000, a negative ROI of almost 65%. This alternative would be considered impractical for firms with this level of down-time sensitivity.
-
Vendor Hot/Cold Site Alternative
The annualized allocated cost and annual expenses of this alternative are approximately equal. Therefore this alternative is a break-even option using the insurance based probability analysis based approach. From a study of the literature it appears that many other firms have also reached this conclusion. The popularity of this contingency planning alternative, as shown by the success of many firms in the backup site business, appears to be based on the decision that we can meet fiduciary duties without it costing anything (e.g.: a break-even low initial cost investment).
-
Own Cold Site Alternative
This alternative clearly leads to a significant negative ROI for this firm. This alternative is normally not authorized to use this approach, except when an old data center is available, thereby eliminating initial costs and creating a break-even situation.
-
No Backup Alternative
This alternative involves almost no expenditure, but leaves the organization open to potentially disastrous losses from loosing their data center. This alternative�s popularity is probably based on the belief that their data center is well protected, and therefore will not be destroyed; as well as the reality that the manual information systems of the organization are in this same condition, and just as critical to the organization�s operations.
-
Summary of BCM Case Study
This case study is not unusual, in that the two methods result in the same recommended decision. The fiduciary responsibility approach normally leads to selection of an acceptable backup plan, while the probability approach, as described in Ozier [5], may sometimes lead to the high risk-no backup approach.
�Threat events having a low-frequency, high-impact risk ... may have a low probability of loss that encourages management to take risks unduly.� This concern about possible high risk approaches is also illustrated by the case study described in Engemann & Miller [2, pp. 143]. �Finally, management felt that qualitative factors related to the marketplace reaction to a severe loss that resulted from inadequate contingency plans had to be factored into the analysis, even if such losses were eventually covered by insurance.�
CONTENTS OF A USABLE BUSINESS CONTINUITY MANAGEMENT PLAN
The critical elements in a usable BCM Plan are the team organization and procedures needed to efficiently move to the backup location and resume productive work, and the backup facilities and equipment that can actually be used to perform the critical business functions affected by the disaster (Rosenthal and Himel [8].
Functions of BCM Teams
Most organizations with mature Business Continuity Management have a three tier BCM team organization structure including:
-
Top tier - Policy Group
-
Second tier - Disaster Management Team (DMT)
-
Third tier - Emergency Response Teams (ERT)
The top tier Policy Group consists of upper-level executives who are available for approving major DMT decisions involving customer service impact, major expenditures or major potential liabilities. For example, after the Bay Area earthquake a major bank opened their branches the next day without power and full cleanup and repairs. The ability to provide much needed cash to customers was deemed more important than the potential for accidents or robberies.
The middle tier DMT includes representatives of key departments and functions involved in life-safety and business contingency planning. The following table lists the functional organizations often represented on a DMT. Selecting the chairperson of the DMT is often a difficult and politically sensitive decision. The pressure to appoint a senior executive should be resisted. Senior executives belong in the Policy Group among their peers. The chair of the DMT, and therefore the coordinator of the EOC, should be an extremely knowledgeable peer of the other members of the DMT. The chair should not however, be associated with any ERT. The chair is frequently the supervisor of the Project Head, Business Continuity Planning.

The third tier consists of a large number of Emergency Response Teams (ERT). For example, the data processing area might have specialized logistics, backup data center operations, network operations, and user support ERTs. The safety area might include a dozen or more ERTs with first aid and evacuation responsibilities, each headed by a floor warden.
Functions
of a Policy Group
The responsibility of the policy group is to authorize out of the ordinary
expenditures required by emergency operations, as well as to set policies
primarily impacting stockholders and the public. They must take the time to
carefully consider the long term impact of the operational decisions being
made by the DMT and the ERTs. Therefore, the team is made up of a variety of
company 14 executives including legal, public relations, human relations,
and financial experts; and is normally the only team not staffed completely
by personnel with primarily day-to-day operations responsibilities.
Functions of a Disaster Management Team (DMT)
During a disaster the DMT has three primary functions:
-
Life-Safety Management
Coordinates the efforts of emergency response teams to assure the safety of personnel and to minimize the damage to their facilities following a disaster. A life-safety DMT normally is organized for every major facility or campus.
-
Business Continuity Planning
Planning and coordinating emergency operations and restoration of normal operations following a disaster. A business continuity DMT is normally responsible for a total business unit, frequently involving multiple and wide-spread facilities.
-
Operating the EOC
The DMT performs its functions from the organizations Emergency Operations Centers (EOC). EOCs observed by the author are of two basic structural types: the single conference room approach, and the dual room approach.
Conference Room EOC Approach
The most common and least expensive approach is the converted conference room. Large conference rooms at two or more widely separated locations are converted to EOCs. Furnishing and equipment required include:
-
Telephone consoles for each participant; including an EOC rotary line, a dedicated incoming line for each function, and a line for outgoing calls.
-
TVS and radios to monitor news and public announcements.
-
White boards, tack boards, and flip charts.
-
Facility maps and area maps with medical and emergency service facilities identified.
-
Multiple radios with multiple channels for use in communicating with emergency response teams and the outside world. At least one of the EOCs should house a portable satellite communication unit.
-
Room power connected to the building's emergency power system.
-
Food, water, and rest facilities for primary and alternate DMT members. California firms often have Los Angeles and San Francisco EOCs and DMTs because of the possibility of an area wide disaster due to a major earthquake. Other areas of the world may not need this much separation between locations.
Dual Room EOC Approach
The dual room EOC approach provides contiguous space for both the Policy and DMT. A glass wall between the two rooms permits the Policy group to monitor DMT activities and observe status boards and displays. Parallel decision making is enhanced permitting continuous emergency operations control while significant policy decisions are being made.
The dual room EOC is normally used by organizations with frequent operational emergencies, such as utilities exposed to power outages or pipeline breaks. The EOC is used for both operational emergencies and for disasters affecting non-operational facilities and personnel. A second conference room type EOC is also normally available at a site remote from the primary EOC.
EOC testing involves two functions: a periodic walk-through of all equipment by the Project Head- Business Continuity Planning, and periodically performing DMT simulations in the EOC.

Functions of Emergency Response Teams (ERT)
The activities of emergency response teams following an emergency must be closely coordinated and adapt swiftly to the type of disaster and its evolving impacts. Emergency response teams can include such areas as: policy, emergency operations center management (DMT), facility acquisition and management, site and equipment recovery, backup data center operations, logistics and transportation, off-site storage coordination, floor wardens, assembly site coordinators, public/employee communications, telecommunications, finance and insurance, etc. Staffing these teams is a significant problem. Each of the functions of the team (including team leadership and around the clock coverage) must have a primary and backup person assigned.
Work locations must be assigned and intra-team and inter-team communications planning must be assured. Some typical problems follow. Does your plan really define to whom the responsibility to handle each problem has been assigned?
-
Who has the authority to declare a disaster and authorize expenditure of funds?
-
Who decides what to tell BCM team members, other employees, customers, and the media?
-
Is there an inventory of available space and equipment?
-
Have all business functions been prioritized so that the facility acquisition and management team can quickly assign space to displaced organizations?
-
Are the teams staffed and lead by persons with the day-to-day operations knowledge required for effective emergency operations?
-
Are all sites stocked with emergency food, water, medical supplies, and other equipment need following a disaster?
-
Are realistic life-safety and assembly drills periodically conducted at all sites?
-
Are there adequate security arrangements for damaged or evacuated sites?
-
Is there a HELP desk planned with sufficient telephone capacity to properly forward calls from media, employees, family of employees, BCM team members, customers, and suppliers?
-
Are the auditors assuring that up-to-date copies of all critical records and data are stored offsite at a secure facility?
-
Do you really know what your insurance coverage is for damage, injuries, and business interruption?
-
Is there an organization responsible for assuring that all business functions and locations have developed a realistic BCM and is adequately testing both the operational and management aspects of the plan?
The determination of emergency teams� functions and reporting structure is dependent on individual firm and site characteristics. The team structure described is typical of a large operational facility housing several clerical organizations and a major data center with a distant commercial backup data center.
Operations Center BCM Teams
-
Damage Assessment and Recovery Coordination Team
This team evaluates the extent of damage to the facility and informs the DMT of the estimated time required to rebuild the damaged facility. The team then assumes the responsibility for restoring the current facility or creating a new facility. -
Public/Employee Relations and Communications Team
This team consists of personnel and public relations staff with responsibility for collecting information on the status of operations, facilities and personnel and communicating relevant information to the media, employees, customers and vendors. -
Operations Coordination (Help and Scheduling) Team
This team is made up of representatives from each of the functions occupying the damaged facility as well as members from each data processing application support group impacted by the disaster. Their role is to schedule and coordinate initial and continuing emergency operations. -
Administrative Support Team
Responsibilities include providing emergency cash and payments, physical security at damaged and backup sites, commuting & lodging support, handling insurance claims, and keeping records of emergency costs & expenditures.
Operations
Center Life/Safety Teams
These teams are responsible for personnel evacuation or lodging following a
localized or area wide disaster. They often include:
-
Floor Wardens
Staff by volunteer employees trained in first aid and in evacuation methods. Responsible for coordinating the evacuation or lodging of occupants in a specific floor or area, as well as performing first-aid and communicating with the EOC. -
Facility Management Team
Staff by physical plant operations personnel. Responsible for operating or shutting down the facility after a disaster. -
Physical Security Team
Responsible for maintaining security at damaged and at temporary locations.
Information Systems Emergency Operations Teams and Positions
These types of teams are responsible for business resumption of critical functions occupying the impacted facility. The data center emergency operations teams described are also typical of the type of teams and positions often needed by other functions occupying a typical operations center.
-
IS BCM Coordinator
Responsible for coordinating the IS recovery and supervising all other IS BCM teams. Normally is a member of the DMT and is located in the EOC. -
IS Backup Center Operations Team
Responsibilities include computer, data communications, and peripheral operations; establishing the data processing schedule during catch-up; disseminating processing output; and providing the Operations Coordination Team with timely status reports. -
IS Logistics & Supplies Team
Responsibilities include transportation, courier, shipping & receiving, and library & warehousing during emergency operations. This includes retrieval of data, software, and documentation from off-site locations. -
IS Operations Support Team
This multi-discipline team's responsibility is to support emergency IS operations. Staff includes technical (systems software), applications development, and data & voice communications support professional personnel. -
IS Specialized Resources Operation Teams
These teams interface or operate sites with specialized IS resources, such as page printers, micro graphics, and check sorters.
Data Center Backup Architectures
An organization's IS architecture must assure near continuous availability of both data centers and telecommunication networks. Both internal and external resources are available to offer the backup resources needed to assure the high availability required by most business resumption policies.
Data Center Backup Approaches
There are three major approaches to Information Systems (IS) Architectures for protecting critical IS processing from interruptions or disasters. They include the use of a commercial backup data center, the use of multiple in-house data centers, and the distribution of processing to multiple user locations (Rosenthal, 1994).
Using commercial backup data centers
Commercial backup data centers offer facilities that permit reactivation of critical processing within 24-36 hours using their hot site, and reactivation of non-critical processing within 1-2 weeks using their cold site. Organizations with a single data center that can tolerate this type of delay find the use of a commercial backup site both cost effective and practical.
Using multiple in-house data centers
Organizations with a small number (normally two to four) of large decentralized data center locations can often use, within 12-24 hours, development and non-critical processing capacity as backup hot site resources. Rapid upgrading of equipment can be implemented in place of a cold site.
ELECTRONIC ARCHIVAL: A HIGH PROTECTION BACKUP ARCHITECTURE
A cost effective way of reducing recovery time when using a commercial backup site or dual in-house data centers is to implement electronic archival. Daily backup tapes are sent to the backup location for storage. During production processing, validated transactions that cause master file updates are transmitted to the backup location where they are logged using a PC and cassette drive. Following a major interruption or disaster, the backup tapes are loaded and the transactions posted. By using this approach, recovery in 8-12 hours is practical.

A typical architecture for dual data centers using electronic archival is shown in Figure 3. The production data center normally will contain an online and an information center (MIS/DSS) system. The backup (development) center would then contain the development system and space to quickly add an additional system. Recovery after a disaster or major interruption at the production center consists of posting today's transactions from the log tape and activating communication lines terminating at the backup (development) center.
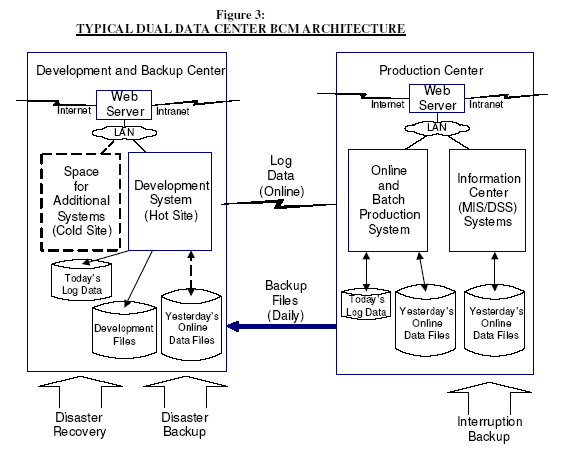
The problem in using multiple in-house data centers to backup each other is in maintaining compatible configurations and systems software versions. Very rigid centralized control of data center configurations and standards is required.
-
Using a distributed processing architecture
Many organizations have dozens to hundreds of similar function facilities. When a data center suffers a disaster, the total facility that it supports is normally also affected. The BCM policy is frequently to shut the facility until repaired, and transfer operations to neighboring locations.
-
Telecommunication Network Backup Approaches
Historically, many organizations have leased voice grade multi-drop telephone lines to support an individual application's data communication requirements. Implementing BCM for networks of multi-drop data lines is often performed by adding an additional drop at the backup data center to each line. When this approach is infeasible because of the distance to the backup center, the dial backup capability of their modems is used to connect both to their data center in the event of a line outage and to the backup center in the event of a disaster.
The recent availability of inexpensive multiplexers and concentrators, and of a wide variety of cost effective high speed lines, has increased the use of trunk connections linking multiple user locations to their data center. Multiple user locations are now being interconnected to data centers through a high speed backbone network that requires a high level of protection from interruptions and disasters. There are two major approaches to assuring high levels of availability for these backbone telecommunication networks. They include building redundancy into the network and/or using switched digital circuits from a common carrier.
-
Using telecommunications network redundancy
High speed trunk oriented data networks based on regional or major site controllers should be configured to include route redundancy. The redundancy is valuable, not just for BCM purposes, but also to handle anticipated load variations and to permit maintenance of equipment and circuits without interrupting service.
-
Using a common carrier's switched broadband circuits
All of the commercial backup data centers have switched circuit capability for connecting the backup center to a customers regional or site communication controllers. In under an hour, several common carriers can reconfigure a client�s network, switching the client data center out of the network and the backup center into the network.
An example of a network using dial backup, network redundancy, and switched broadband circuits is shown in Figure 4. Remote sites are connected to regional concentrators with multiple routes to the data center. These concentrators also have switched broadband capability to connect to the backup center after BCM purposes. Sites or terminals close to the data center have voice grade dial backup capability to reach the backup center.
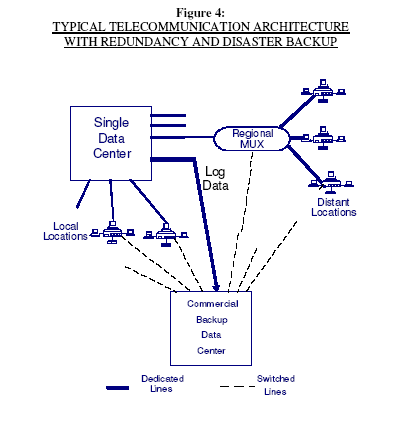
The economics of implementing this type of backbone architecture as part of a BCM program is very favorable. Broadband digital links are highly reliable and starting to be priced at rates highly competitive with multi-drop voice grade lines. Many firms have achieved slight reductions in cost by consolidating their various application oriented networks while simultaneously adding redundancy and/or switched capability to meet BCM requirements.
Manual System Backup Approaches
Backup methods for manual records tend to be expensive and to utilize specialized equipment; or are not very safe. This problem may explain, but does not excuse the lack of effective BCM arrangements for most critical manual systems. The following types of backup methods are only representative of the multitude of architectures available when creative managers are faced with the executive demand for a realistic BCM for all critical business functions. These various backup methods can be categorized based on if the manual processing will continue to be performed on paper or by using other media (primarily micrographic or IT image systems).
Paper-Based Processing Backup Alternatives
Paper based processing seldom survives a quality business process reengineering (BPR) study. However, a BPR is seldom performed unless extensive automation has already occurred in that business unit. Therefore, the following approaches are the most common result of a demand for a BCM.
-
Secure/Fire-Proof File Room or Safe
Only currently being used paper records are to be removed from the file room/safe. This approach gives good protection during non-working hours. However, paper records are seldom removed and returned individually, because of the inefficiencies involved. Also in the event of a fire, earthquake, bomb scare etc., staff does not return current records to the secure area and, in fact, seldom close the rooms/safes. This approach gives only fair protection, and should not pass audit when the records are critical to the survival of the organization. -
Off-Site Storage of Micrographic Copies of Records
Few business processes do not update the majority of records accessed. This approach, therefore, is seldom used. It is however, very effective and safe and should be used when feasible.
Archiving Off-Site the Original Paper Records and Transactions
This type of processing involves the use of non-computer based storage for processing media. The most common types of media are microfilm/microfiche and image mass storage systems,are:
-
Micrographic media for use in processing is very common when most activity is requests for information, and all actions generate new records that can be filmed and archived. This approach, when applicable, is very effective and safe.
-
Image Systems are normally used for the same type of applications as micrographic media. The can, however, automatically index new transactions affecting a master record. This permits their use in more applications than micrographic systems. This approach, when applicable, is also very effective and safe
CONCLUSION
Business Continuity Management should be an integrated portion of a total security program. The security program should cover physical security of facilities and equipment, data security of automated files and manual records, protection of all levels of personnel, and Business Continuity Management. Business Continuity Management needs to be an integral part of doing business. For example, IBM internal policy -as stated in their Corporate Disaster Recovery Planning Standard (Policy Number 209) directs all operating and staff units of the company to develop plans for any emergency that results in either a significant loss of assets or revenue flow, or renders the organization unit unable to meet customer commitments or protect the interests of stockholders and employees.
Executives of all organizations have a fiduciary responsibility to take prudent steps to assure the survival of their organization following a natural or man-made disaster. Providing the necessary funds and leadership for a quality Business Continuity Management program for all critical business functions, both IS and manually oriented, is a key portion of that responsibility.
Paul H. Rosenthal is a professor of information systems at California State University, Los Angeles. He has BS in Ed and an MA from Temple University, an MBA from UCLA, and a DBA from USC; and has been active in the Information Systems, Computing Science, and Scientific Computing areas for 48 years as a programmer, manager, consultant, and academic. His current research interests encompass the manual and computerized infrastructure aspects of mission-critical transaction processing systems.
L. Jane Park is a professor of accounting at California State University, Los Angeles. She has a BS from the University of Texas, an MS from the University of Houston, a Ph.D. from the University of Illinois, and a CPA certification. Her current research interests include accountants� soft-skills requirements and the impact of IT on accounting processes.
Jan I. Weissman, formally a lecturer in information systems at California State University, Los Angeles, is currently a technology instructor and coordinator at Brentwood School. She has a BSBA in finance from California State University, Northridge, an MSBA in Information Systems from California State University, Los Angeles, holds a California primary teaching credential, and has over two decades of experience as a programmer, supervisor, administrator and teacher.
BIBLIOGRAPHY
1. Andrews, W.C. "Contingency Planning for Physical Disasters", Journal of
Systems Management, 41:7, 28-32, July 1990. A short but comprehensive
description of the why and how of justifying and producing a data center BCM.
2. Engemann, Kurt J., and Holmes E. Miller. �Operations Risk Management at a
Major Bank,� Interfaces, 22:6: 140-49, November-December 1992. Presents a
decision analysis framework for making risk management decisions.
3. Lamond, B.J. "An Auditing Approach to Disaster Recovery", Internal Auditor, 47:5, 38-48, October 1990. A survey of the DRP preparation cycle including an introduction to operational testing and plan maintenance.
4. Metzger, Michael B., et al. Business Law and the Regulatory Environment: Concepts and Cases. Chicago: Richard D. Irwin, Inc.: 867-69, 1995. This book defines the �duty of care� and �fiduciary responsibility� of officers and directors of corporations. It states that the Model Business Corporation Act requires officers to act in good faith, and with the care a prudent person, in a like position, would exercise under similar circumstances, as well in a manner they reasonably believe to be best interest of the corporations.
5. Ozier, Will. �Issues in Quantitative vs. Qualitative Risk Analysis,� Managing IT/IT Solutions. Delran: Datapro Information Services Group, report 6055 (1994): 1-7. A detailed comparison of the quantitative (probability) and qualitative (fiduciary responsibility) approaches and their impact on managerial decisions.
6. Rohde, R. and Haskett, J. "Disaster Recovery Planning for Academic Computing Centers", Communications of the ACM, 33:652-657, 1990. A step by step description of producing a BCM for a university data center.
7. Rosenthal, P. �The Emerging Enterprise Systems Architecture�, Journal of Systems Management, 45:2; 16-21, February 1994.
8. Rosenthal, P. and Himel, B. "Business Continuity Management: Exercising Your Emergency Response Teams", Computers & Security, 10:497-514, 1991. A detailed description of a data center disaster plan�s simulation testing including a complete script of an actual exercise.
9. Rosenthal, P, and Sheiniuk, G. �Exercising the Business Disaster Team�, Journal of Systems Management, 38:4; 12-16 & 38-42, 1993. A detailed description of a business continuity and life-safety disaster plan�s simulation testing including a complete script of an actual exercise.
10. Waldman, Jan I. A Methodology for Justification of Business Continuity Management Based on Fiduciary Responsibility Considerations, Unpublished masters thesis, California State University, Los Angeles, 1995. A detailed description, with examples, of the use of the prudent person BCM justification approach.
11. Wong, K. K. Risk Analysis and Control - A Guide for DP Managers, Hayden Book Company Inc., 1997. The classic presentation of the quantitative approach to risk analysis. Contains a description of the statistical, IBM, and NCC [National Computing Center] approaches to risk evaluation, as well as a good description of risk control.
For
Further Information
Contact
Dr. Paul Rosenthal
Information Systems Department, ST603
California State University, Los Angeles
5151 State University Drive
Los Angeles, CA 9032-8123
[email protected]
![]() Click Here
for The Business Forum Library of
White Papers
Click Here
for The Business Forum Library of
White Papers
![]()
 Search Our Site
Search Our Site
Search the ENTIRE Business
Forum site. Search includes the Business
Forum Library, The Business Forum Journal and the Calendar Pages.
Disclaimer
The Business Forum, its Officers, partners, and all other
parties with which it deals, or is associated with, accept
absolutely no responsibility whatsoever, nor any liability,
for what is published on this web site. Please refer to:
Home
Calendar
The Business Forum Journal
Features
Concept
History
Library
Formats
Guest Testimonials
Client Testimonials
Experts
Search
News Wire
Join
Why Sponsor
Tell-A-Friend
Contact The Business Forum
The Business Forum
Beverly Hills, California United States of America
Email: [email protected]
Graphics by DawsonDesign
Webmaster:
bruceclay.com
� Copyright The Business Forum Institute 1982 - 2009 All rights reserved.
![]()